LLM Model Drift: The Silent Threat to AI ROI
Most enterprises deploy LLMs and hope for the best. But model drift is a silent threat—eroding accuracy, trust, and ROI. At SolvIT AI, we help you catch drift before it costs you.
The "Drift Gap" in LLM Operations
Model drift happens when your LLM’s performance degrades due to changing data, user behavior, or external factors. The result? Less accurate, less relevant, and sometimes unsafe outputs.
- Missed Monitoring: No one is watching for subtle performance drops.
- Slow Retraining: Models go stale before anyone notices.
- Weak Feedback Loops: End-user input isn’t captured or acted on.
How to Stop Model Drift:
- Monitor Continuously: Track outputs and key metrics in real time.
- Automate Alerts: Get notified at the first sign of performance drop.
- Retrain Regularly: Use fresh data to keep models sharp.
- Close the Feedback Loop: Capture and act on user input.
Immediate ROI Impact:
SolvIT AI’s managed AI-Ops keeps your LLMs accurate, safe, and valuable from day one.
Understanding the Three Types of LLM Model Drift
Not all model drift is the same, and treating them identically is a common mistake. There are three distinct drift patterns in production LLMs, each requiring a different detection strategy and remediation approach.
Data Drift (Input Distribution Shift)
The types of queries or inputs your LLM receives change over time — new topics, different vocabulary, shifting user intent. A customer service LLM trained in 2023 may have never seen questions about your 2025 product line. The model doesn't fail catastrophically; it just becomes progressively less accurate. Detection: monitor the distribution of input embeddings over time. A significant shift in the embedding centroid signals data drift before accuracy degrades.
Concept Drift (World Knowledge Staleness)
The world changes but the model's knowledge doesn't. Regulatory requirements update, market conditions shift, organizational policies change. An LLM giving compliance advice based on outdated regulations creates real liability. Detection: structured evaluation datasets with known-correct answers, run on a weekly cadence. Accuracy drop on these "sentinel questions" is an early warning signal before users notice.
Feedback Loop Drift (RLHF Corruption)
Models fine-tuned on human feedback can drift if the feedback quality degrades. Annotators get tired, feedback criteria shift, or adversarial users game the rating system. Over time the model optimizes for what gets positive feedback — which may no longer align with what's actually correct or helpful. Detection: inter-annotator agreement scores, feedback audits, and periodic comparison against a held-out ground truth set.
The Business Cost of Undetected Drift
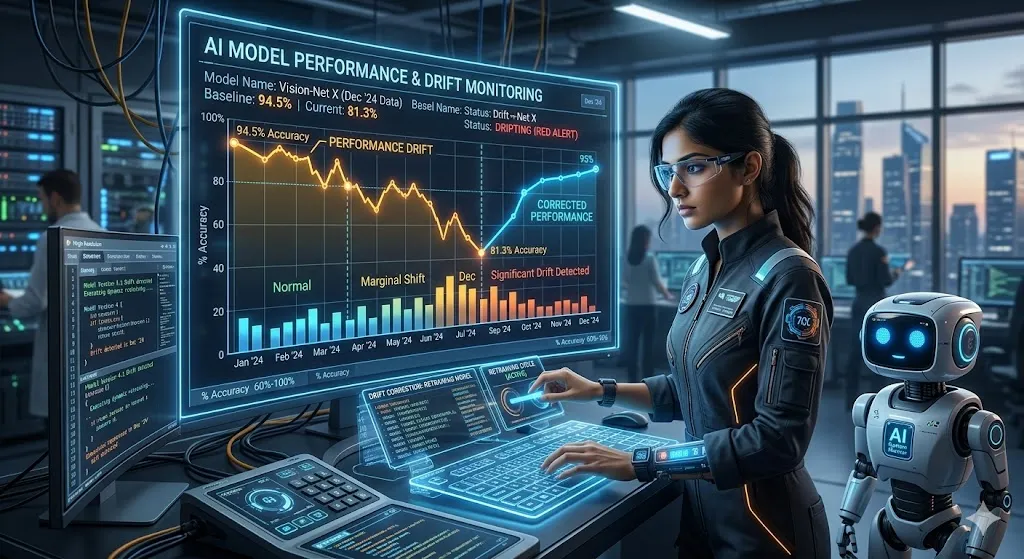
Model drift rarely announces itself with a system failure. It's insidious — performance degrades gradually, and by the time business metrics visibly suffer, the damage is already done. Consider a realistic drift scenario: a mid-market financial services firm deploys an LLM for loan application pre-screening. In month one, accuracy is 94%. By month six, undetected drift has dropped it to 79%. The firm has spent six months making credit decisions on a model that's increasingly wrong — and has no audit trail showing when the degradation started.
The Hidden Cost Multiplier
Organizations that detect drift after it impacts business outcomes spend 3–5x more on remediation than those that detect it early. Early detection means targeted retraining on a small dataset. Late detection means full model audit, regulatory disclosure (in some industries), customer remediation, and reputational repair. The monitoring infrastructure pays for itself many times over.
Building a Drift Detection Stack: What to Monitor and How
An effective production monitoring stack for LLMs has four layers, each catching drift that the others miss:
- Statistical Distribution Monitoring: Track input embedding distributions, output confidence distributions, and token-level statistics. Flag deviations beyond 2σ from the training baseline. Tools: Evidently AI, WhyLabs, or custom embedding drift detectors.
- Evaluation Dataset Cadence: Maintain a curated set of 500–2,000 representative input/output pairs with known-correct answers. Run the current model against this set weekly. A 3%+ accuracy drop triggers an investigation.
- Production Sampling & Human Review: Sample 1–5% of live model outputs for human quality review. Track the human-override rate (how often reviewers correct the model). A rising override rate is the earliest leading indicator of drift.
- Business Metric Correlation: Map model performance metrics to the business KPI the model is supposed to drive. If the KPI moves but the technical metrics don't, or vice versa, something is misaligned. This layer catches "teaching to the test" failures that technical metrics miss.
Retraining Strategy: When to Retrain and How Much
Retraining too frequently wastes compute and risks introducing new errors. Retraining too infrequently allows drift to compound. The right answer depends on the domain. For a customer service LLM in a fast-changing product company, monthly retraining cycles are common. For a legal document summarization model in a stable regulatory environment, quarterly is often sufficient.
When you retrain, always use a mix of fresh data and curated historical data — not just the most recent records. Recent data can be noisy or unrepresentative, and models trained only on recent data often lose capability on the full distribution. Validate on a held-out test set that spans the full historical range before promoting a retrained model to production. See our Managed AI-Ops guide for details on continuous optimization cycles.
Structuring Your Drift Response Protocol
Drift detection without a response protocol is expensive alerting. A complete managed AI-Ops program pairs monitoring with a tiered decision framework:
- Green — No Drift: Performance within thresholds. Continue scheduled monitoring and monthly sentinel evaluation.
- Yellow — Early Signal: Statistical distribution shift or 2–5% accuracy decline. Initiate investigation. Review recent input distribution changes. Collect labeled examples for potential retraining. Escalate to model owner.
- Orange — Significant Drift: Greater than 5% accuracy decline or rising human override rate. Activate retraining pipeline. Consider shadow deployment of candidate model against production volume. Notify downstream system owners.
- Red — Critical Drift: Model output is creating business risk or compliance exposure. Immediate rollback to last stable version. Human takeover of affected workflow. Post-incident review within 48 hours. Stakeholder notification per incident response protocol.
What You Need Before Deploying Drift Monitoring
Drift monitoring requires three organizational capabilities that many enterprises lack at the point they're asking about it: a curated evaluation dataset with verified correct outputs updated at least annually; a reproducible retraining pipeline that can ingest fresh data and produce a new model artifact in a defined timeframe; and a model registry with tested rollback procedures so a previous version can be restored within minutes of a red-level event. Building these three capabilities is the foundation of Phase III: Managed AI-Ops.
Key Takeaways
- Three distinct drift types: data drift (input distribution shift), concept drift (world knowledge staleness), and feedback loop drift (RLHF corruption). Each requires a different detection strategy.
- Drift is insidious. By the time business metrics visibly suffer, the damage has been compounding for weeks or months. Early detection costs 3-5x less to remediate.
- 4-layer monitoring stack: statistical distribution monitoring, evaluation dataset cadence, production sampling with human review, business metric correlation.
- 3 organizational prerequisites before monitoring: a curated evaluation dataset, a reproducible retraining pipeline, and a model registry with rollback capability.
- Retraining frequency depends on domain volatility. Monthly for fast-changing environments; quarterly for stable ones. Always mix fresh and curated historical data.
Related reading: Preventing LLM Model Drift in Production | Managed AI-Ops: Mid-Market ROI | SolvIT Managed AI-Ops Service
Ready to stop model drift before it starts?
Get a rapid LLM health check and actionable plan for continuous value.
Book Your Free AI-Ops AssessmentRelated reading: The Real ROI of Enterprise AI | 66% Error Reduction | Preventing LLM Drift